池化层
池化通常也被称为下采样(Downsampling),一般是用在卷积层之后,通过池化来降低卷积层输出特征图的维度,有效减少网络参数的同时还可以防止过拟合现象。
所谓池化层(Pooling)就是将特征图下采样,
作用是对感受域内的特征进行筛选,提取区域内最具代表性的特征,能够有效地降低输出特征尺度,进而减少模型所需要的参数量。
主要功能有以下几点:
- 抑制噪声,降低信息冗余
- 提升模型的尺度不变性、旋转不变形
- 降低模型计算量
- 防止过拟合
按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受域内最大、平均与总和的特征值作为输出,最常用的是最大池化,也即是MaxPooling。根据相关研究,特征提取的误差主要来自于两点:
邻域大小受限造成的估计值方差增大。
卷积层参数误差造成估计均值的偏移。
一般来说,平均池化可以减少第一种误差,更多的保留图像的背景信息,而最大池化可以降低第二种误差,更多的保留图像的纹理信息。总结一下,池化层优点有:
不变性,更关注是否存在某些特征而不是特征具体的位置。可以看作加了一个很强的先验,让学到的特征要能容忍一些的变化。(实际上这个容忍能力是非常有限的)
减少下一层输入大小,减少计算量和参数量。
获得定长输出。(文本分类的时候输入是不定长的,可以通过池化获得定长输出)
防止过拟合或有可能会带来欠拟合。
说了这么多池化的优点,那么它有什么缺点吗?
语义分割任务中,多次下采样会使得图像中某些目标细节丢失,结果不精细。
池化层实际上真正起作用的地方在于他的非线性映射能力和可以保持一定量的 平移不变性 的能力。
这个能力是因为在一个图像区域有用的特征很有可能在另一个区域同样有用。因此,为了描述一个大分辨率的图像特征,一个直观的方法就是对大分辨率图像中的不同位置的特征进行聚合统计。
具体来说,常见池化的方法有以下几种:
- 标准池化:
通常包括最大池化 (MaxPooling)、平均池化 (Mean Pooling)、随机池化(Stochastic pooling)、中值池化。以最大池化为例,池化核尺寸为,池化步长为,可以看到特征图中的每一个像素点只会参与一次特征提取工作。 - 重叠池化
操作和标准池化相同,但唯一不同地方在于滑动步长小于池化核的尺寸,可以想象到这样的话特征图中的某些区域会参与到多次特征提取工作,最后得到的特征表达能力更强。这个过程可以表示为下图: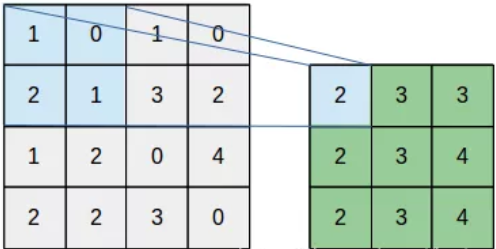
- 空间金字塔池化 Spatial Pyramid Pooling
用于解决重复卷积计算和固定输出的两个问题。
这种池化是在进行多尺度训练的时候,对不同输出尺度采用不同的滑窗大小和步长以确保输出尺度相同,同时用如金字塔式叠加的多种池化尺度组合,以提取更加丰富的图像特征。空间金字塔池化可以用下图表示: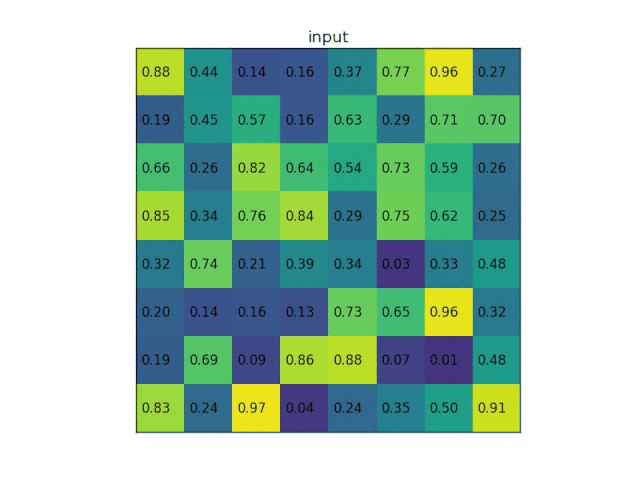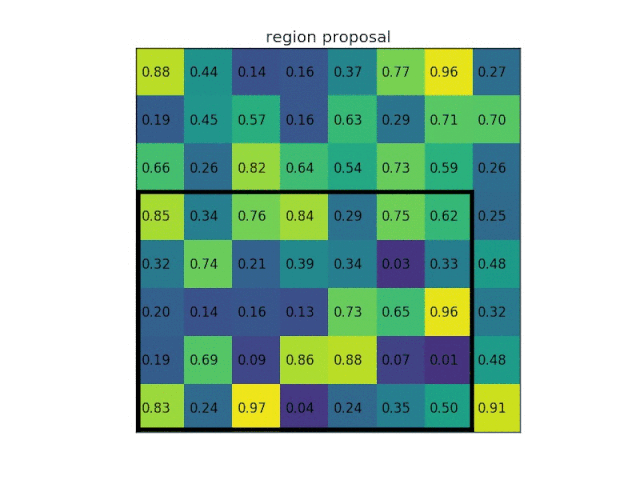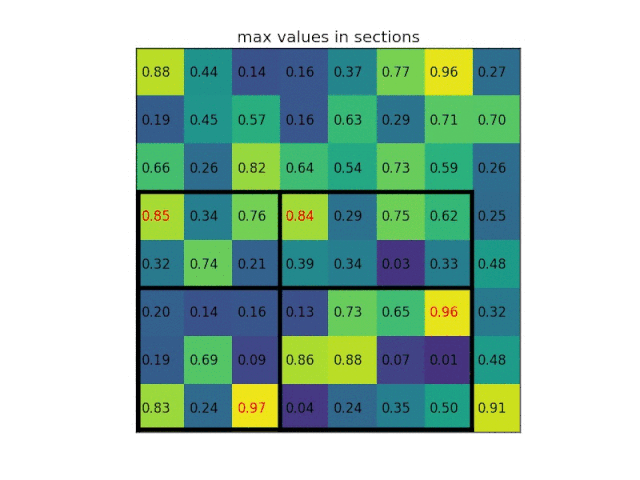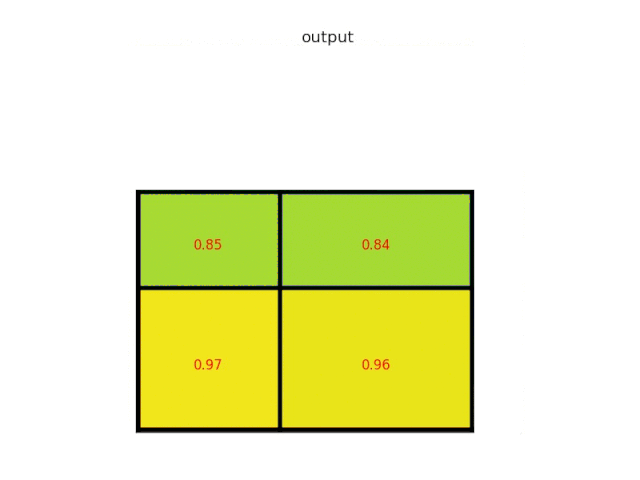
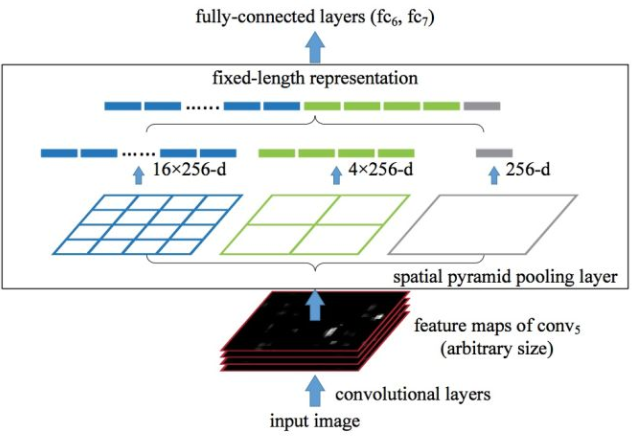
SPP的优点还有:- 可以提取不同尺寸的空间特征信息,可以提升模型对于空间布局和物体变性的鲁棒性。
- 可以避免将图片 resize、crop 成固定大小输入模型的弊端。
resize、crop有啥弊端呢?
一方面是resize会导致图片中的物体尺寸变形
另一方面,crop 会导致图片不同位置的信息出现频率不均衡,例如图片中间的部分会比角落的部分会被 CNN 看到更多次(卷积重复计算)。
- 组合池化
常见组合策略有两种:Cat与Add。 - 全局平均池化 Global Average/Max Pooling
UnPooling 是一种上采样操作,具体操作如下:
- 在Pooling(一般是Max Pooling)时,保存最大值的位置。
- 中间经历若干网络层的运算。
- 上采样阶段,利用第1步保存的Max Location,重建下一层的feature map。
UnPooling不完全是Pooling的逆运算,Pooling之后的feature map,要经过若干运算,才会进行UnPooling操作;对于非Max Location的地方以零填充。然而这样并不能完全还原信息。
全局平均池化(GlobalAvgPooling),这是用来做什么的?
请多多指教。
文章标题:池化层
本文作者:顺强
发布时间:2019-10-12, 23:59:00
原始链接:http://shunqiang.ml/cnn-pooling/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

