HRNet
图像处理的粒度不同,适用不同的问题场景
HRNet通过并行连接高分辨率到低分辨率卷积来保持高分辨率表示,并通过重复跨并行卷积执行多尺度融合来增强高分辨率表示。在像素级分类、区域级分类和图像级分类中,证明了这些方法的有效性。
(1) 并行连接高分辨率到低分辨率的子网,而不是像大多数现有解决方案那样串行连接。因此,我们的方法能够保持高分辨率,而不是通过一个低到高的过程恢复分辨率,因此预测的热图可能在空间上更精确。(parallel high-to-low resolution subnetworks)
(2) 大多数现有的融合方案都将低层和高层的表示集合起来。相反,HRNet使用重复的多尺度融合,利用相同深度和相似级别的低分辨率表示来提高高分辨率表示,反之亦然,从而使得高分辨率表示对于姿态的估计也很充分。因此,预测的热图可能更准确。(multi-resolution subnetworks (multi-scale fusion))
Stem
# stem net
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=False)
# self.layer1 = self._make_layer(block, 64, num_channels, num_blocks)
self.layer1 = self._make_layer(Bottleneck, 64, 4)

特征融合的方式: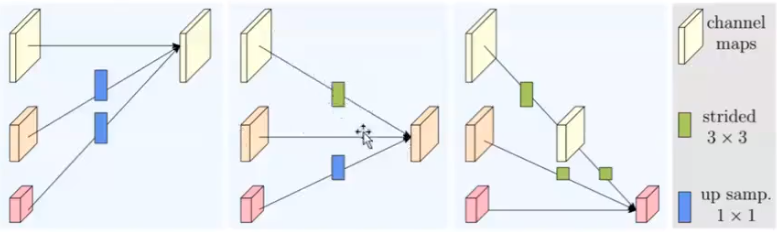
HRNetW32 意思是 channel 的数量,表格中的 C
不同的 head 应用于不同的场景
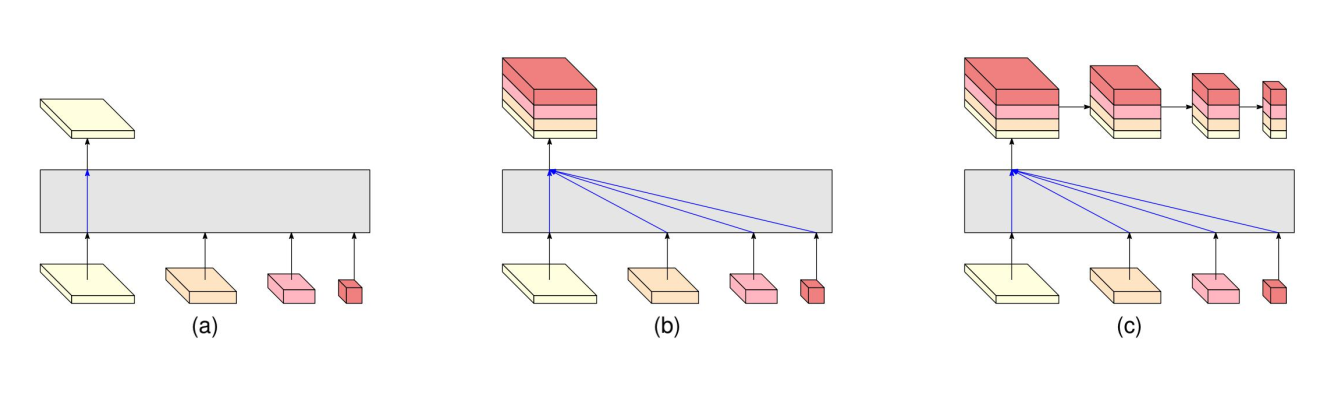
v1 Human Pose Estimation
The output is the representation only from the high-resolution stream. Other three representations are ignored
regress the heatmaps simply from the high-resolution representations output by the last exchange unit, which empirically works well.
This means that only a subset of output channels from the high-resolution convolutions is exploited and other subsets from low-resolution convolutions are lost
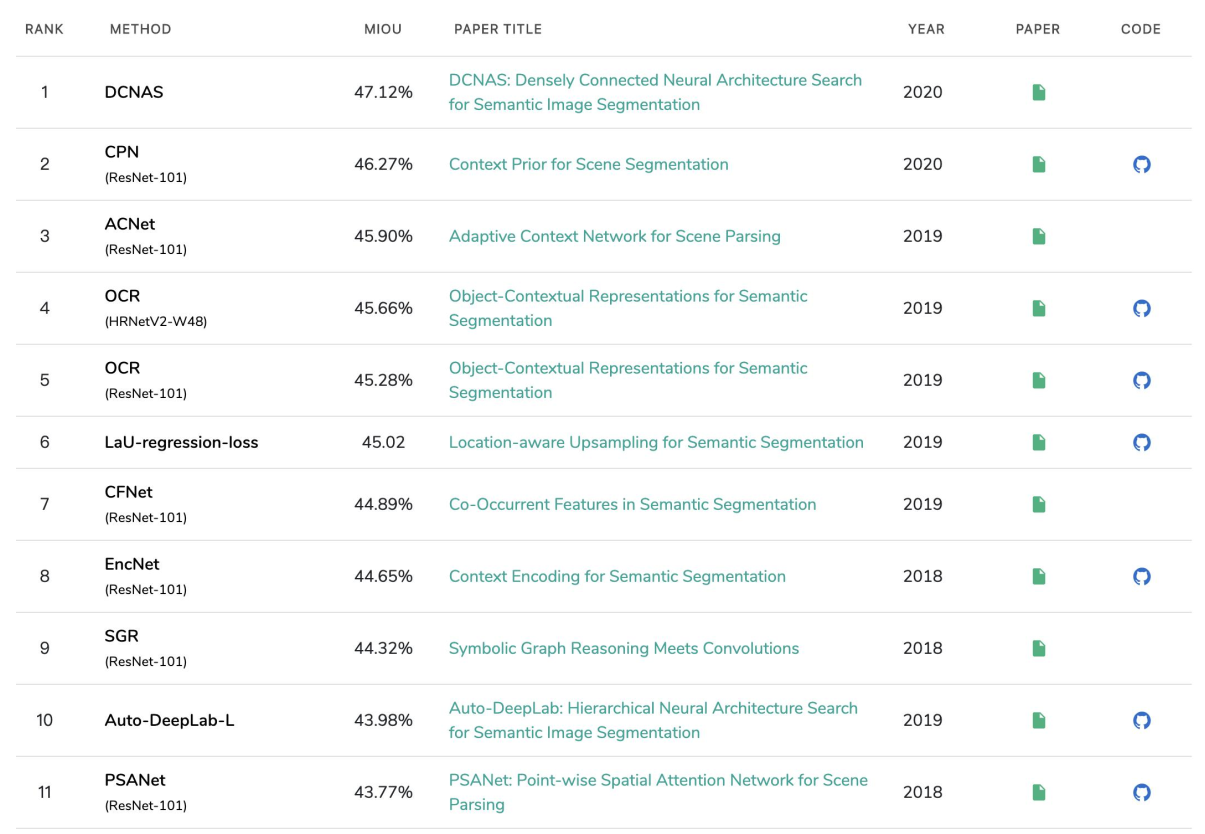
v2 全景分割 = 语义分割 + 实例分割
We rescale the low-resolution representations through bilinear upsampling without changing the number of channels to the high resolution, and concatenate the four representations, followed by a 1 × 1 convolution to mix the four representations.
语义分割技术方向,对象上下文 (Object Context) , 利用一个像素周围的信息进行判断。
V2p Object Detection
We construct multi-level representations by downsampling the high-resolution representation output from HRNetV2 to multiple levels.
参考资料:
• Deep High-Resolution Representation Learning for Visual Recognition
• Deep High-Resolution Representation Learning for Human Pose Estimation
• High-Resolution Representations for Labeling Pixels and Regions
• https://github.com/HRNet
• https://github.com/rbgirshick/yacs
• https://github.com/openseg-group/openseg.pytorch
请多多指教。
文章标题:HRNet
本文作者:顺强
发布时间:2020-02-18, 23:59:00
原始链接:http://shunqiang.ml/paper-hrnet/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

